
Künstliche Intelligenz ist ein Überbegriff für Anwendungen bei denen Maschinen menschenähnliche Intelligenzleistungen erbringen. Darunter fällt das Maschinelle Lernen und das Deep Learning. Beim Maschinellen Lernen lernt die „KI“ durch Training mit Daten welche die Zielgrößen/Targets enthält (Überwachtes Lernen), beim unüberwachten Lernen erkennt die „KI“ selbständig Muster in den Daten und beim Reinforcement Lernen lernt die „KI“ durch Belohnung und Bestrafung.
Beim Deep Learning werden sehr tiefe Strukturen an neuronalen Netzen aufgebaut um komplexe Entscheidungen wie z.B. unübersichtliche Verkehrssituationen richtig zu interpretieren.

Abb: Definition Künstliche Intelligenz
Der Einsatz von KI ist keine Science-Fiction und nicht auf die Lösung von Brettspielen oder auf die Verwendung in Computerspielen beschränkt, sondern es lassen sich mit KI bestehende Industrieprozesse optimieren und neue innovative Produkte und Lösungen schaffen, welche die Wettbewerbsfähigkeiten der Unternehmen wesentlich verbessern.
Beispiele hierfür sind die vorausschauende Wartung, die Optimierung von Regelkreisen und die Detektion von Anomalien. Werden z.B. KI-basierte Regelkreise in Heizungssystemen eingesetzt, können die Energiekosten ohne weitere Sanierungsmaßnahmen um 20% gesenkt werden.
Laut Sundar Pichai, dem CEO von Google, ist KI eine der wichtigsten Technologien an denen Menschen aktuell arbeiten und die Bedeutung übersteigt die von Elektrizität und Feuer.
Rund um KI existieren viele Ängste, Bedenken und überzogene Erwartungen. Daher gilt es folgendes festzuhalten:
- Künstliche Intelligenz ist keine Magie
- Es handelt sich um klar definierte, mathematische Algorithmen deren Ergebnisse durch die Eingangsdaten eindeutig bestimmt sind
- Künstliche Intelligenz kann nicht schlauer sein als ihre Datenbasis (Garbage in – Garbage out)
- Künstliche Intelligenz entwickelt sich nicht selbständig weiter
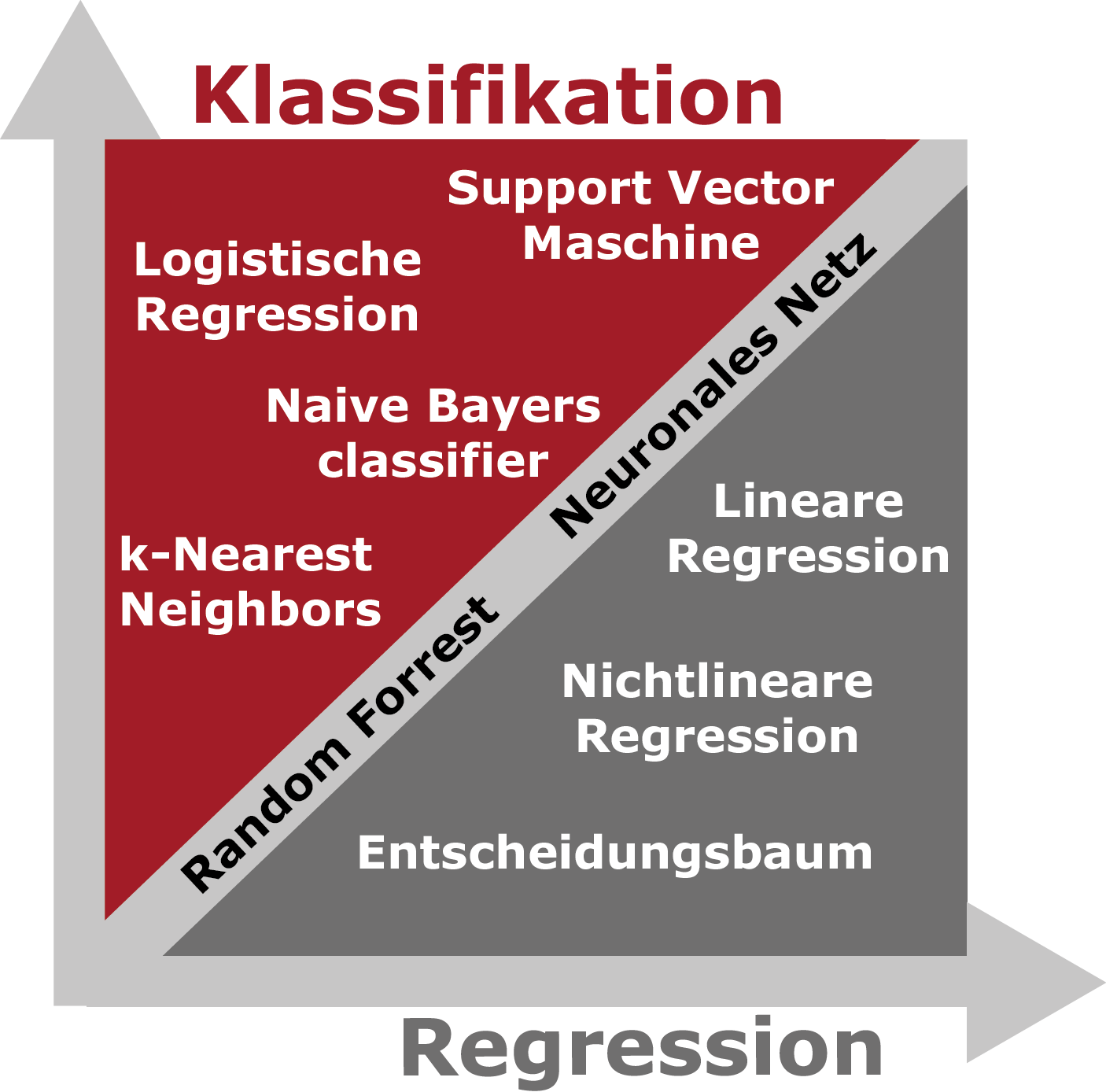
Überwachtes Lernen: Beim Überwachten Lernen unterscheidet man im Wesentlichen zwischen zwei Methoden: Der Regression und der Klassifikation. Mittels Regression sind Vorhersagen kontinuierlicher Werte möglich (z.B. Sensorwerte). Die Klassifikation liefert hingegen diskrete Ausgangswerte (Produktkategorien, Fehler/kein Fehler,…)
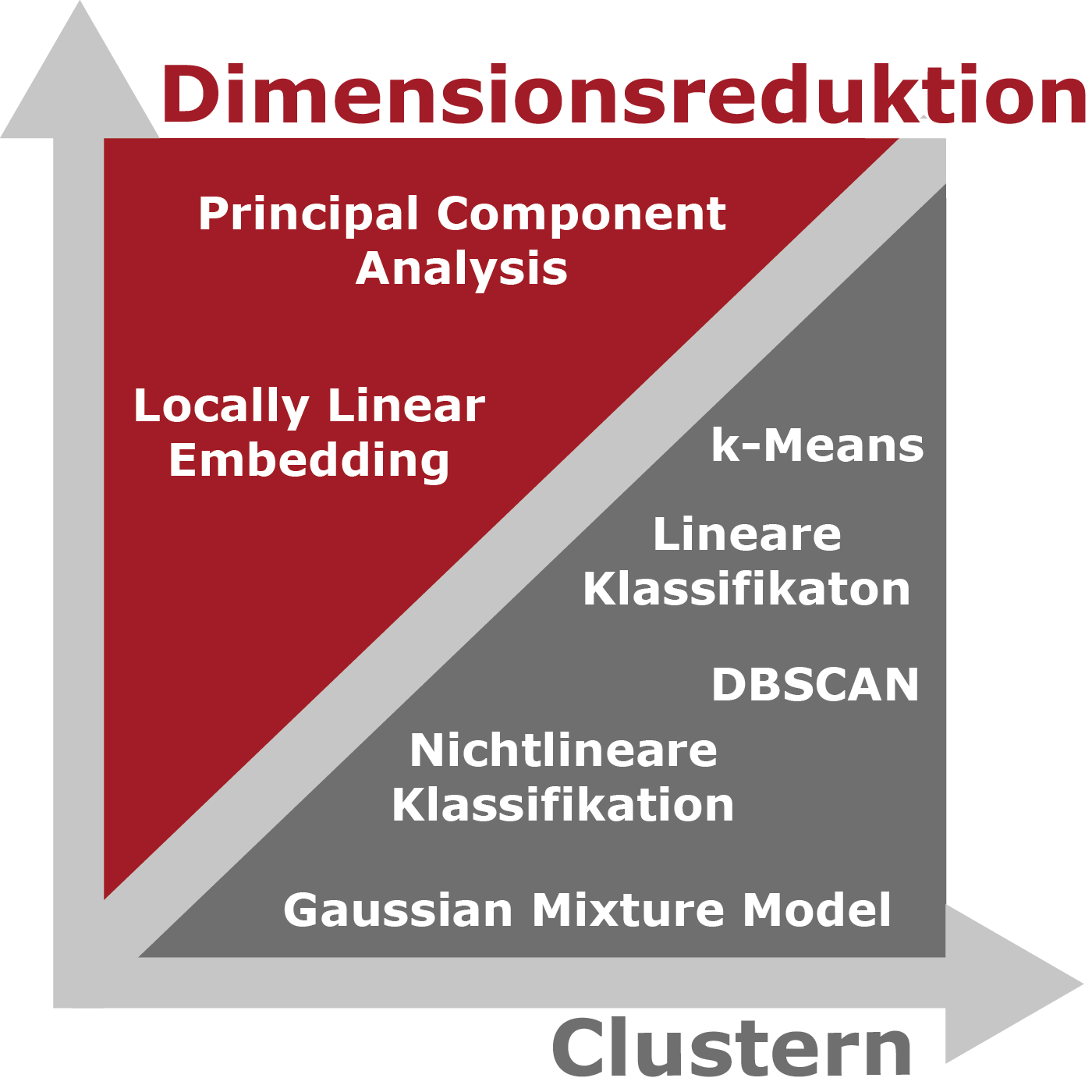
Unüberwachtes Lernen: Das unüberwachte Lernen wird in die Methoden Clustering und Dimensionsreduktion eingeteilt. Mittels Clustering lassen sich Muster in den Daten erkennen, um Handlungsempfehlungen zu generieren oder die Daten zu gruppieren. Mittels Dimensionsreduktion lassen sich multidimensionale Daten auf zwei oder drei Dimensionen zur Visualisierung reduzieren und Rauschen in den Messwerten kann entfernt werden. Die Dimensionsreduktion wird somit häufig zur Aufbereitung der Daten für andere Modelle eingesetzt.
Verstärkendes Lernen: Beim verstärkenden Lernen lernt der Agent der „KI“ Belohnungen zu maximieren. Grob wird verstärkendes Lernen anhand der Agenten-Strategie in Modellfreie Methoden wie Monte-Carlo, Temperal Difference Learning und in strategiebasierte Methoden wie Reinforce und Trust Region Policy Optimization eingeteilt. Verstärkendes Lernen kann eingesetzt werden, wenn das Modell der Umgebung bekannt ist, eine Simulationsumgebung vorhanden ist oder wenn nur durch Aktionen Informationen über die Umgebung gewonnen werden können. Anwendung findet verstärkendes Lernen z.B. bei Sortierrobotern.
Leistungsfähige Softwarewerkzeuge, welche den AnwenderInnen bei der Analyse der Daten bis zur Entwicklung des KI-Modells unterstützen, erlauben Erfolge bereits innerhalb von Tagen zu erzielen anstatt monatelanger Entwicklung.
Es ist nicht erforderlich ein Data Scientist zu sein, um den besten Algorithmus selbständig auszuwählen und zu parametrieren. Verwenden Sie stattdessen zur Optimierung ihrer Prozesse und Anlagen unsere On-Prem Analytik Lösung Proficy CSense und unsere Cloud Lösung TUGinsight.